以 有道精品课为例,视频文件为 .ts 文件,下载后也无法合并,因为使用了 AES-128 加密。因此核心处理思路是,下载 .m3u8 文件,根据此文件下载 .ts 文件。然后在 下载加密的key 文件。最后使用 key + ts 合并。
前置内容
1. 先下载 .mu38 文件
打开视频页面,在network 中搜索 .mu38 即可看到链接,访问链接即可下载 .mu38 文件
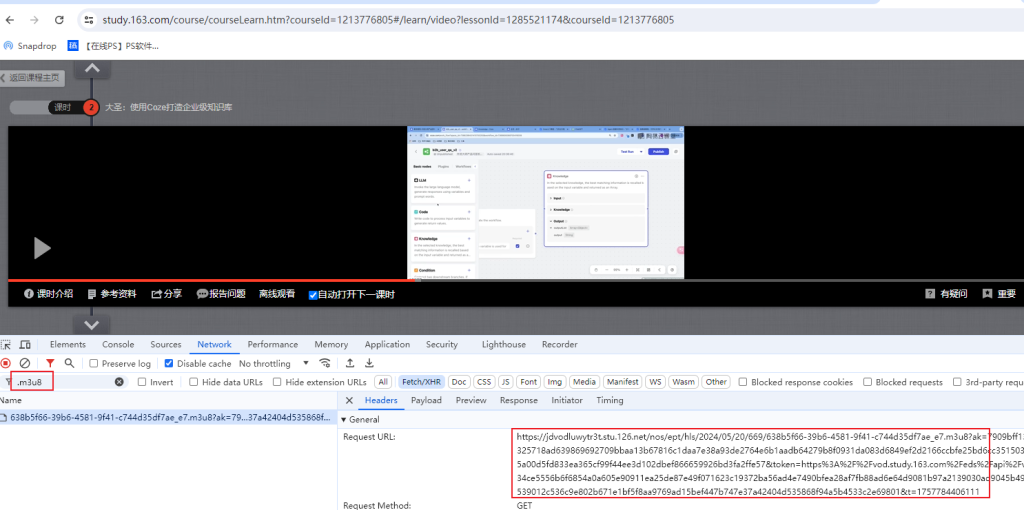
.m3u8 文件的内容如下
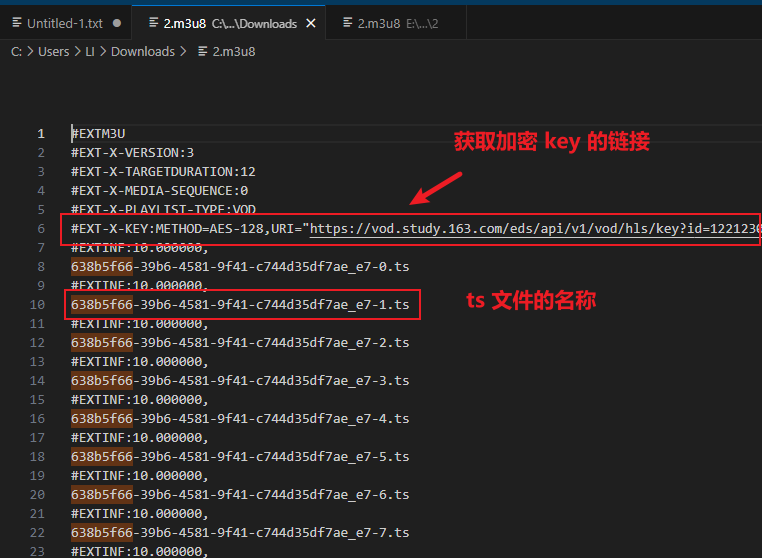
2.下载 key 文件
在 network 中搜索 /key 即可看到链接,但此链接直接在浏览器访问无法下载。
这里使用js 进行下载。
先找到加载此文件的js代码
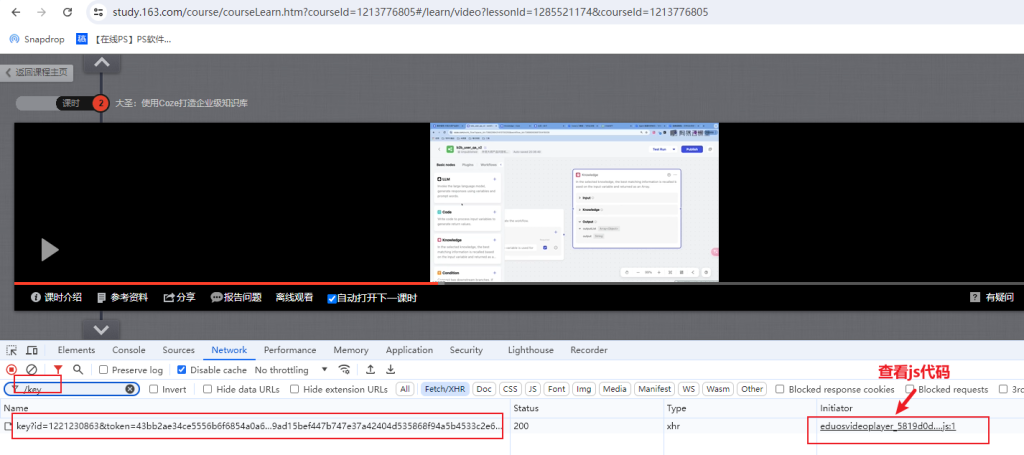
在文件加载完成后的处理逻辑中,找到合适位置打断点。
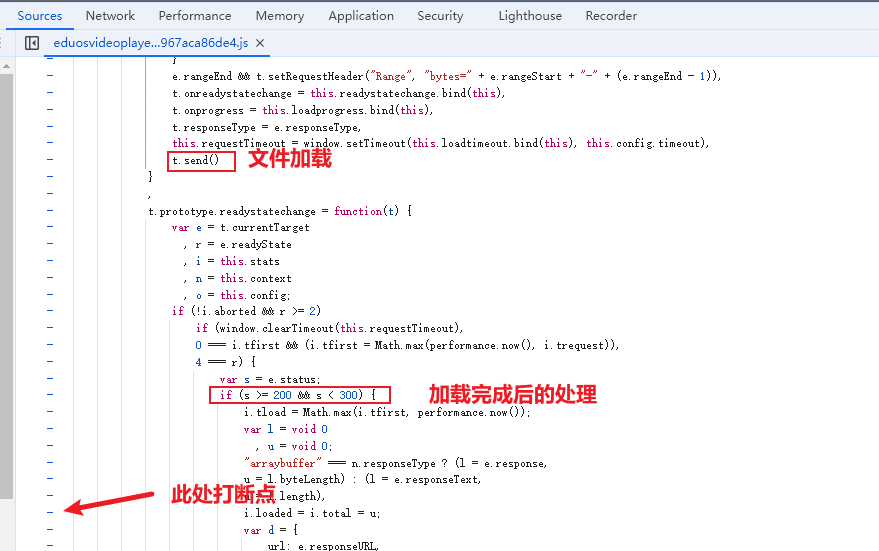
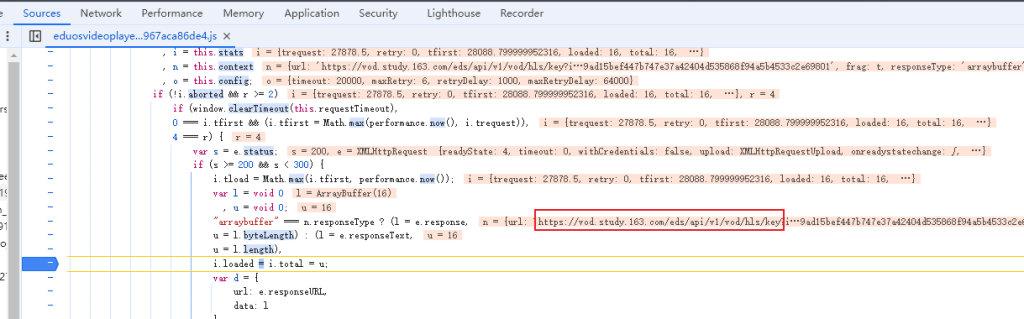
然后刷新页面,程序执行到断点处会停止,点击继续执行,直到url 为我们需要的 hls/key 时为止
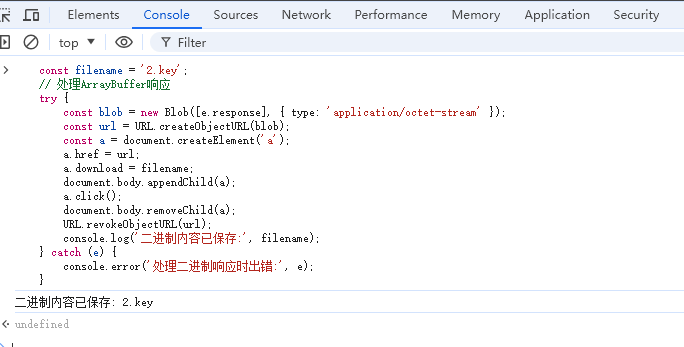
在 console 中输入如下代码,即可下载 key 文件
# 注意 控制台如果报错,不允许输入代码,可先输入 allow pasting 回车。
# 然后输入如下代码 即可。
const filename = '2.key';
// 处理ArrayBuffer响应
try {
const blob = new Blob([e.response], { type: 'application/octet-stream' });
const url = URL.createObjectURL(blob);
const a = document.createElement('a');
a.href = url;
a.download = filename;
document.body.appendChild(a);
a.click();
document.body.removeChild(a);
URL.revokeObjectURL(url);
console.log('二进制内容已保存:', filename);
} catch (e) {
console.error('处理二进制响应时出错:', e);
}
至此前置条件准备完成。
前置内容-篡改猴
前置内容使用篡改猴一次性快速下载,并完成内容的替换。
使用下载器下载
获取到 .m3u8 和 key 后,直接使用下载器,即可下载。

下载后,解压即可使用。打开软件
先将 key 拖入窗口,在弹出的窗口中,选择 是
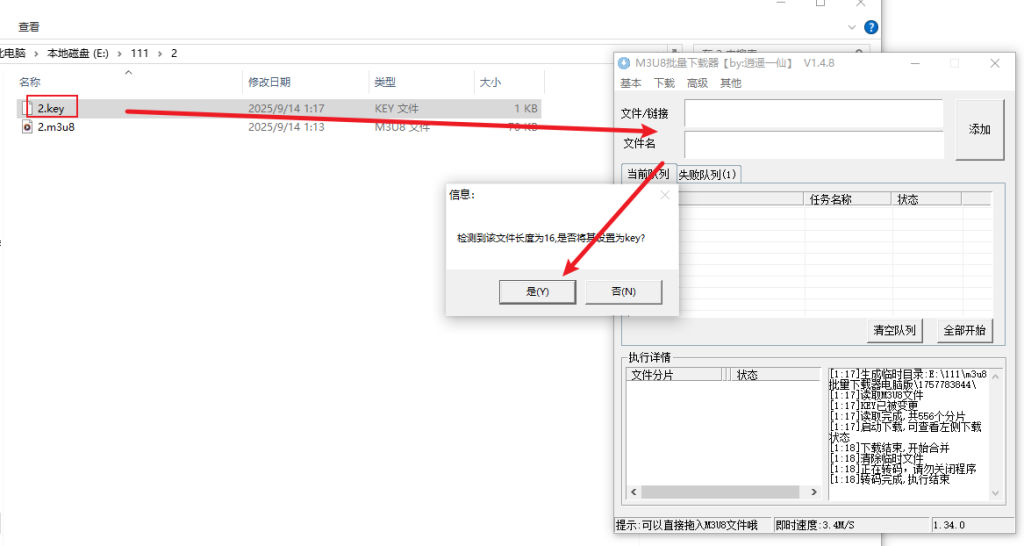
再将 .m3u8 文件拖入窗口,然后点击 添加
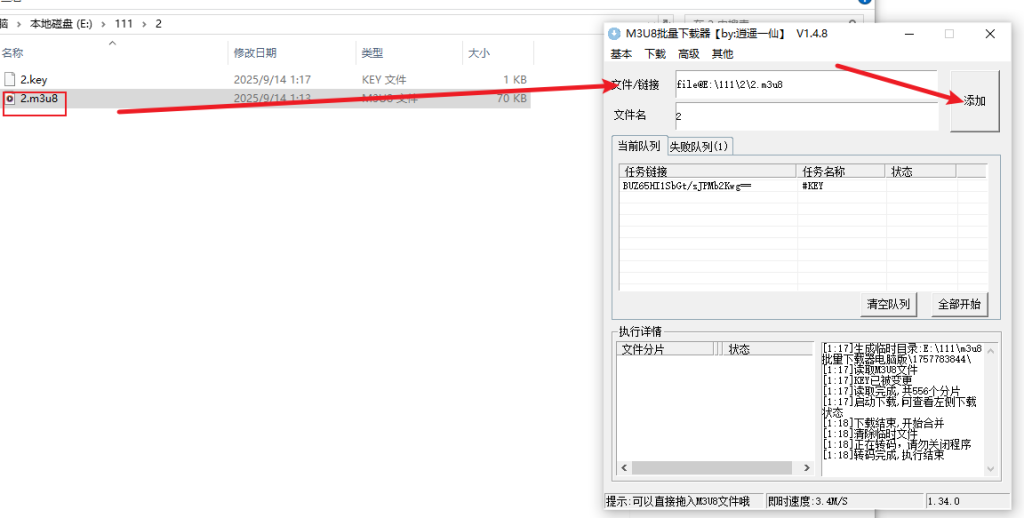
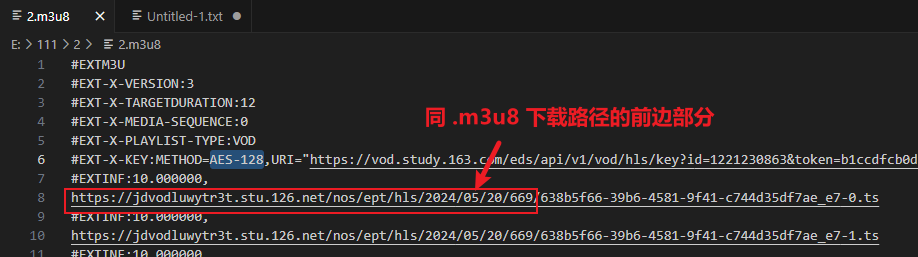
注意:.m3u8 中的 ts 使用的时相对路径,使用这个批量工具需要把路径替换为全路径
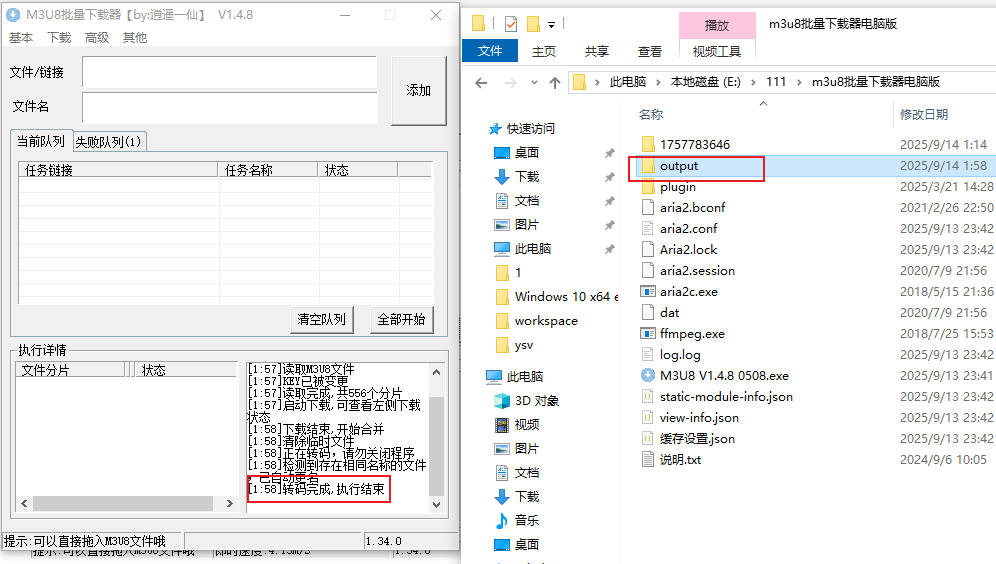
点击全部开始,即可开始 ts 文件的下载。
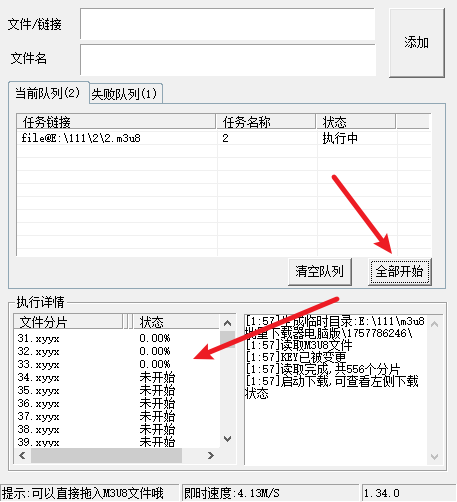
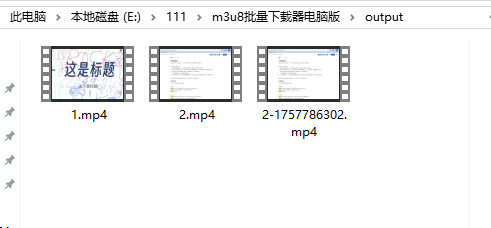
提示执行结束后,在软甲目录下的 output 即可看到合并后的文件。
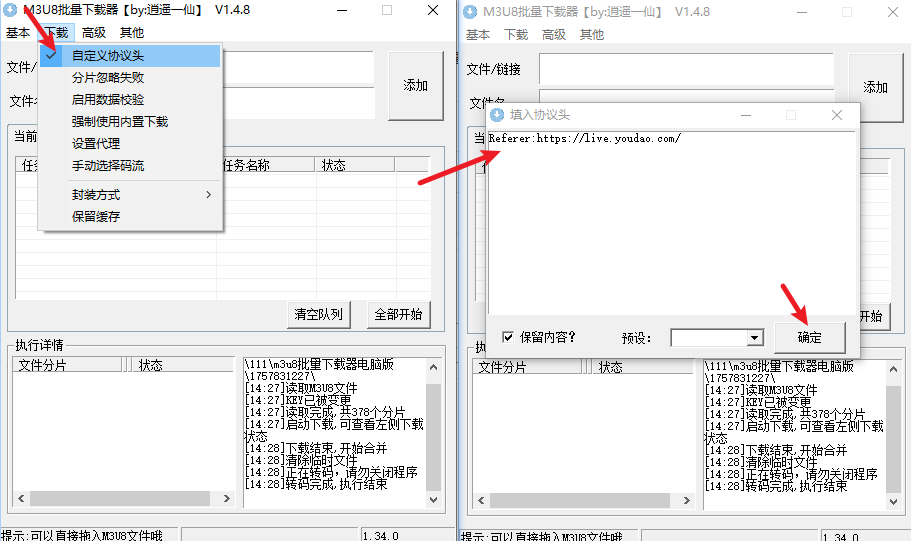
对于有道精品课,下载 ts 时需要增加 header , 按如下方式添加 Referer 即可。
使用python下载
1.安装 ffmpeg
[查看安装教程](http://www.maersi.fun/2023/12/04/ts%e6%96%87%e4%bb%b6%e4%bd%bf%e7%94%a8-python%e5%90%88%e5%b9%b6/)
2.使用 js 下载 .m3u8 和 key
[查看教程](http://www.maersi.fun/2025/09/14/m3u8-%e6%96%87%e4%bb%b6%e4%b8%8b%e8%bd%bd/)
3.使用 python 下载 ts 文件, 合并视频。
pyhton main.pyimport os
import requests
import sys
import concurrent.futures
from pathlib import Path
import subprocess
from Crypto.Cipher import AES
import re
from tqdm import tqdm
class TSDownloaderMerger:
def __init__(self, filename="", output_dir=""):
self.output_filename = filename + '.mp4'
self.output_dir = os.path.join(output_dir)
self.temp_dir = os.path.join(output_dir, filename)
self.key = None
self.iv = None
Path(self.temp_dir).mkdir(exist_ok=True)
def get_decryption_key_local(self, key_file_path):
"""从本地文件获取AES解密密钥"""
try:
# 检查密钥文件是否存在
if not os.path.exists(key_file_path):
print(f"密钥文件不存在: {key_file_path}")
return False
# 从本地文件读取密钥
with open(key_file_path, 'rb') as f:
self.key = f.read()
print(f"成功从本地文件读取解密密钥,长度: {len(self.key)} 字节")
return True
except Exception as e:
print(f"读取本地密钥文件失败: {e}")
return False
def parse_m3u8(self, file_path):
"""解析本地m3u8文件,提取TS文件列表
参数:
file_path: 本地m3u8文件路径
返回:
TS文件URL列表,如果解析失败则返回None
"""
try:
# 从本地文件读取内容
with open(file_path, 'r', encoding='utf-8') as f:
content = f.read()
# 查找所有TS文件行
ts_lines = re.findall(r'^[^#].*\.ts', content, re.MULTILINE)
ts_urls = ts_lines
return ts_urls
except Exception as e:
print(f"解析m3u8文件失败: {e}")
return None
def decrypt_ts(self, encrypted_data, sequence_number):
"""解密TS数据,改进的PKCS7填充处理"""
try:
# 如果没有显式指定IV,则使用序列号作为IV
if self.iv:
iv = self.iv
else:
# 默认使用序列号作为IV(16字节)
iv = sequence_number.to_bytes(16, byteorder='big')
# 确保encrypted_data的长度是16的倍数(AES块大小)
if len(encrypted_data) % 16 != 0:
# 补齐到16的倍数
padded_len = ((len(encrypted_data) // 16) + 1) * 16
encrypted_data = encrypted_data.ljust(padded_len, b'\x00')
cipher = AES.new(self.key, AES.MODE_CBC, iv)
decrypted_data = cipher.decrypt(encrypted_data)
# 改进的PKCS7填充去除
if len(decrypted_data) > 0:
pad_len = decrypted_data[-1]
# 验证pad_len是否在有效范围内(1-16)
if 1 <= pad_len <= 16:
# 验证所有填充字节是否都等于填充长度
if all(decrypted_data[-i] == pad_len for i in range(1, pad_len + 1)):
return decrypted_data[:-pad_len]
# 如果填充验证失败,返回原始解密数据(不进行裁剪)
return decrypted_data
except Exception as e:
print(f"解密失败: {e}")
# 解密失败时记录错误并返回空字节,而不是原始加密数据
return b''
def download_single_ts(self, url, filename, sequence_number=0):
"""下载并解密单个TS文件"""
try:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36',
'Referer': 'https://live.youdao.com/'
}
response = requests.get(url, headers=headers, timeout=30)
response.raise_for_status()
# 如果有密钥,则解密数据
if self.key:
decrypted_data = self.decrypt_ts(response.content, sequence_number)
with open(filename, 'wb') as f:
f.write(decrypted_data)
else:
# 无加密直接保存
with open(filename, 'wb') as f:
f.write(response.content)
# print(f"成功下载: {filename}")
return True
except Exception as e:
print(f"下载失败 {url}: {e}")
return False
def download_all_ts(self, ts_urls):
"""使用多线程下载所有TS文件,显示下载进度(tqdm版本)"""
total_files = len(ts_urls)
print(f"开始下载 {total_files} 个TS文件...")
# 准备下载任务
download_tasks = []
for i, url in enumerate(ts_urls):
filename = os.path.join(self.temp_dir, f"{os.path.basename(url)}")
download_tasks.append((url, filename, i))
# 使用线程池并发下载(限制并发数避免被封IP)
success_count = 0
# 使用tqdm创建进度条
with tqdm(total=total_files, desc="下载进度", unit="file") as pbar:
with concurrent.futures.ThreadPoolExecutor(max_workers=5) as executor:
futures = []
for url, filename, seq_num in download_tasks:
futures.append(executor.submit(self.download_single_ts, url, filename, seq_num))
for future in concurrent.futures.as_completed(futures):
if future.result():
success_count += 1
# 无论成功与否,都更新进度条
pbar.update(1)
print(f"下载完成: {success_count}/{total_files} 个文件成功")
return success_count == total_files
def extract_key_url(self, m3u8_content):
"""从m3u8内容中提取密钥URL"""
match = re.search(r'#EXT-X-KEY:METHOD=AES-128,URI="([^"]+)"', m3u8_content)
if match:
return match.group(1)
return None
def create_file_list(self, ts_urls):
# 创建文件列表
filelist_path = os.path.join(self.temp_dir, "file_list.txt")
with open(filelist_path, 'w', encoding='utf-8') as f:
for ts_file in ts_urls:
f.write(f"file '{os.path.basename(ts_file)}'\n")
def merge_with_ffmpeg(self):
"""使用FFmpeg合并TS文件(推荐)"""
if not self.check_ffmpeg():
print("未找到FFmpeg,请先安装FFmpeg并添加到系统路径")
return False
try:
# 创建文件列表
filelist_path = os.path.join(self.temp_dir, "file_list.txt")
# 使用FFmpeg合并
cmd = [
'ffmpeg', '-f', 'concat', '-safe', '0',
'-i', filelist_path, '-c', 'copy', self.output_filename
]
print("开始合并TS文件...")
result = subprocess.run(
cmd,
cwd=self.output_dir,
capture_output=True, # 捕获为字节而非文本
check=True
)
# 如果需要可以手动解码
try:
output = result.stdout.decode('GBK')
except UnicodeDecodeError:
output = result.stdout.decode('GBK', errors='ignore')
print(output)
if result.returncode == 0:
print(f"合并成功! 输出文件: {self.output_filename}")
return True
else:
print(f"合并失败: {result.stderr}")
return False
except subprocess.CalledProcessError as e:
print(f"FFmpeg错误: {e.stderr}")
return False
except Exception as e:
print(f"合并过程中出错: {e}")
return False
def check_ffmpeg(self):
"""检查系统是否安装了FFmpeg"""
try:
subprocess.run(['ffmpeg', '-version'], capture_output=True, check=True)
return True
except (subprocess.CalledProcessError, FileNotFoundError):
return False
def cleanup(self):
"""清理临时文件"""
import shutil
if os.path.exists(self.temp_dir):
shutil.rmtree(self.temp_dir)
print("临时文件已清理")
def main(m3u8_url):
# 获取 m3u8 文件名称(包含扩展名)
m3u8_filename = os.path.basename(m3u8_url)
m3u8_basename = os.path.splitext(m3u8_filename)[0]
print(f"文件名称: {m3u8_basename}")
# 获取目录路径
directory_path = os.path.dirname(m3u8_url)
print(f"目录路径: {directory_path}")
# 下载ts
downloader = TSDownloaderMerger(f"{m3u8_basename}", directory_path)
try:
# 0. 获取 ts 文件列表
ts_urls = downloader.parse_m3u8(m3u8_url)
print(f"ts文件数量: {len(ts_urls)}")
# 1. 获取解密密钥(如果需要)
if not downloader.get_decryption_key_local(os.path.join(directory_path, m3u8_basename + '.key')):
print("无法获取解密密钥,可能无法正确解密视频")
else:
print("成功获取解密密钥")
# 2. 下载所有TS文件(会自动解密)
if not downloader.download_all_ts(ts_urls):
print("下载过程中出现问题,可能部分文件未成功下载")
# 3.创建 file_list.txt
downloader.create_file_list(ts_urls)
print("file_list 已经创建")
# 4. 合并文件(优先尝试使用FFmpeg)
if downloader.check_ffmpeg():
success = downloader.merge_with_ffmpeg()
else:
print("FFmpeg未安装")
if success:
print("视频处理完成!")
else:
print("视频处理失败!")
# 5. 是否清理临时文件(取消注释以下行来启用清理)
downloader.cleanup()
except KeyboardInterrupt:
print("用户中断操作")
except Exception as e:
print(f"程序执行出错: {e}")
if __name__ == "__main__":
# 单个文件下载
# main(r'E:\111\【有道博闻美育】高端文学·秋实班\04.茅盾文学奖之《东藏记》一.m3u8')
# 批量下载
directory = r'E:\111\【有道博闻美育】高端文学·秋实班'
# 遍历目录下的所有文件
for filename in os.listdir(directory):
# 检查文件是否为m3u8文件
if filename.endswith('.m3u8'):
# 构建完整的文件路径
file_path = os.path.join(directory, filename)
print(f"\n\n当前文件: {file_path} =================================\n\n")
# 调用main函数处理该文件
main(file_path)